Every layer of Granite 4.1 in one conversation
At the IBM Booth at THINK 2026, we ran a demo that a visitor could have walked past without realizing what it was. A microphone, a pair of speakers, a screen showing a grid of checkmarks. You spoke to it, it spoke back. Voice agents are everywhere now; the novelty was what happened between the two turns.
Behind that microphone, every model family in the Granite 4.1 release was doing its job on the same conversation. Granite Speech was transcribing. A Granite language model was answering. Granite Switch was hot-swapping LoRA adapters from the Granite Core and Guardian Libraries to score each answer against a list of requirements. Mellea was orchestrating the whole thing. The grid on the screen was live: every response you heard had already been validated against criteria we defined, or rejected and retried, before the first phoneme reached the speaker.
This post is how that demo is put together, and why stitching every layer into one artifact mattered more to us than any one layer on its own.
The problem we set for ourselves
Real-time voice agents are a good stress test for a model stack. They are intolerant of latency. They are intolerant of spoken-word formatting failures (nobody wants to hear a bulleted list read aloud). They are also a natural venue for the safety and grounding questions enterprise customers care about: did the model stay on topic, did it stay in scope, did it avoid a category of output you asked it to avoid.
What we wanted to know was whether we could build one pipeline in which each of those concerns was handled by a piece of Granite 4.1 that shipped this week, with no hand-waving and no glue we would be embarrassed to show a developer. No "pretend this guardrail is running." No "imagine the STT is local." Everything real, on one machine or one cluster, talking to each other through a single application.
The pipeline
The backbone is Pipecat, an open-source pipeline framework for real-time media. Audio enters over WebRTC, flows through a chain of FrameProcessor stages, and leaves over WebRTC. Each stage is a small, swappable component:
Browser mic → WebRTC → Silero VAD → Granite Speech (STT) → UserAggregator → Mellea (LLM + validation) → TTS → WebRTC → Browser speaker
At the booth we ran against hosted endpoints: a vLLM speech endpoint served ibm-granite/granite-speech-4.1-2b for STT, a vLLM agent endpoint served ibm-granite/granite-switch-4.1-3b-preview as the chat model, and a Watson TTS server handled synthesis; the open source reference ships with Kokoro to keep the dependency footprint open. Validation was on by default, with a UI toggle to flip back to streaming on demand.
Each WebRTC connection spawns its own pipeline instance, so a second visitor walking up to the microphone gets an isolated conversation with its own context, its own epoch counters, and its own validation state.
Granite Speech: hearing the room
The speech leg of the stack is the one that gets tested hardest at an event like THINK. Exhibition halls are loud. Lanyards brush against microphones, speakers trail off, and a 15-second pause is common; so is a barge-in three words into the response.
ibm-granite/granite-speech-4.1-2b handles transcription. It's a compact, multilingual speech-language model: three components composed into one 2B-parameter checkpoint. A 16-block Conformer encoder with a dual-head CTC objective (graphemic and BPE outputs side by side) reads 80-channel logmel features in 4-second blocks. A two-layer Q-Former projector downsamples 10× to a 10 Hz acoustic embedding rate, and feeds those embeddings into a Granite 4.0 1B base model that has been jointly fine-tuned with the encoder. The result is a single model that does ASR and bidirectional speech translation across English, French, German, Spanish, Portuguese, and Japanese, and prints punctuation and truecasing (including German noun capitalization) as part of its native output rather than as a post-processing pass.
The training set is 174,000 hours of audio drawn from LibriHeavy, Multilingual LibriSpeech, VoxPopuli, CommonVoice, YODAS, ReazonSpeech, and a synthetic Japanese ASR corpus, plus 21,000 hours of paired translation data. The reported mean WER on the Open ASR Leaderboard is 5.33, with an RTFx of 231. Throughput at the booth was never the bottleneck.
Two of the model's properties matter directly for a live voice demo. The first is keyword biasing, which is built into the model rather than bolted on. The demo's vocabulary is dense with "Granite," "Mellea," "Switch," and "LoRA," which the model is unlikely to prioritize without a hint, so we pass those terms as part of the transcription prompt and let the model bias decoding toward them:
prompt = (
"transcribe the speech with proper capitalization and punctuation. "
"The following terms may appear in the audio: "
+ ", ".join(STT_KEYWORD_BIAS)
)
The model's training data includes synthetic examples of exactly this prompt shape, so the biasing is a first-class capability, not a hack we discovered.
The second is barge-in handling. If the host starts talking over the bot, Pipecat's VAD fires a VADUserStartedSpeakingFrame, the pipeline bumps an epoch counter, and any STT response already in flight (possibly for a half-sentence the user abandoned) is dropped when it lands. The turn strategy only ever sees transcripts from the current epoch. This is invisible when it works and catastrophic when it doesn't. A stale "uh, what I was going to say..." appended to the real question will send the LLM in a different direction.
Mellea: orchestrating the turn
Above the speech layer, Mellea handles the conversation. Mellea is the Python library IBM Research is coalescing around for what they call "generative programs": applications where LLM calls are first-class operations governed by requirement verifiers and principled repair loops, not ad-hoc prompt chains and brittle agents. The framing is deliberate. An LLM call inside a normal application is an unreliable subroutine that produces silent failures, untestable outputs, and no performance guarantees. Mellea's job is to give that subroutine the same shape as the rest of your program.
The pattern at the heart of Mellea is Instruct, Validate, Repair ---
IVR, which is also the name of the toggle the demo exposes in its UI.
The shape is simple: instruct the model, validate the output against
declared requirements before it leaves the session, and repair by
re-sampling with failure feedback when validation fails. Requirements
are declared as plain-English RequirementSpec subclasses, and they
can be checked by an LLM verifier, by a programmatic Python function,
or by a domain-trained adapter, all three behind the same interface.
The repair step is configurable: rejection sampling, best-of-N,
majority voting, and SOFAI are swappable in one line, which means
scaling reliability is a knob you turn rather than a rewrite.
That last piece is what makes Mellea the right glue for this demo. When we wire up Granite Switch's Core- and Guardian-Library adapters in the next section, we don't write any adapter-specific plumbing. We declare requirements, hand them to Mellea, and let it route the verification through whichever adapter each spec names. Different reliability strategy? Different requirement source? Same call site.
In the demo, the requirements are short, plain English, and exactly the kind of thing that's hard to enforce by prompting alone:
IVR_REQUIREMENT_SPECS: list[RequirementSpec] = [
RequirementCheckSpec(
label="Natural speech",
description="The response consists of short, complete sentences that sound natural when spoken aloud.",
instruction="Use short, complete sentences that sound natural when spoken aloud.",
),
RequirementCheckSpec(
label="No markdown",
description="The response contains no bullet points, no numbered lists, no headers, and no markdown formatting.",
instruction="No bullet points. No numbered lists. No headers. No markdown formatting.",
),
PolicyGuardrailSpec(
label="Relevant to IBM",
description="The response is relevant to IBM offerings.",
instruction="Stay relevant to IBM offerings.",
policy_text=(
"Responses must be relevant to IBM products, services, or offerings. "
"General-knowledge answers unrelated to IBM violate this policy."
),
ambiguous_passes=True,
),
RequirementCheckSpec(
label="No code",
description="The response includes software code or pseudocode or offers to help with coding",
instruction="",
invert=True,
),
]
Two things in that list are worth pulling apart. First, each spec carries
both a description (used at validation time to score the answer) and
an instruction (joined into the system prompt so the model sees the
rule during generation). One requirement, two surfaces: tell the model
what to do, and separately, check that it did. Second, the no-code spec
sets invert=True with an empty instruction. Telling a voice model
"do not write code" is the kind of negative instruction that often
backfires; better to say nothing during generation and just reject
candidates that slip in code after the fact.
The two concrete spec types route to two different adapters in Granite
Switch. RequirementCheckSpec calls the Core Library's
requirement_check intrinsic and thresholds a calibrated 0–1 score.
PolicyGuardrailSpec calls the Guardian Library's policy_guardrails
intrinsic, which returns one of Yes, No, or Ambiguous for whether
the response satisfies a free-form policy. Both subclass the same
abstract RequirementSpec base and expose the same check() interface,
so the IVR loop doesn't need to know which adapter it's invoking:
@dataclass(frozen=True, kw_only=True)
class RequirementCheckSpec(RequirementSpec):
"""Validates via the requirement-check ALoRA. Returns a float score
thresholded against `threshold` (or `< threshold` when `invert` is set)."""
threshold: float = DEFAULT_REQUIREMENT_THRESHOLD
invert: bool = False
def check(self, gen_ctx, backend):
score = core.requirement_check(gen_ctx, backend, self.description)
passed = score < self.threshold if self.invert else score > self.threshold
return passed, float(score), self.threshold
@dataclass(frozen=True, kw_only=True)
class PolicyGuardrailSpec(RequirementSpec):
"""Validates via the policy-guardrails ALoRA. Returns a Yes/No/Ambiguous
label, mapped to a pseudo-score for uniform reporting."""
policy_text: str
ambiguous_passes: bool = False
def check(self, gen_ctx, backend):
label = guardian.policy_guardrails(gen_ctx, backend, policy_text=self.policy_text)
passing = {"Yes", "Ambiguous"} if self.ambiguous_passes else {"Yes"}
passed = label in passing
score = {"Yes": 1.0, "Ambiguous": 0.5, "No": 0.0}.get(label, 0.0)
return passed, score, 0.5
The ambiguous_passes=True on the IBM-relevance check is deliberate.
Voice agents at a noisy booth will produce plenty of replies that are
arguably on-topic; failing them all on uncertainty would make the bot
silent. We let Ambiguous through and only reject a hard No.
The default streaming path of the demo skips validation entirely. Tokens arrive, get pushed downstream as LLMTextFrames, and Pipecat's sentence-aggregating TTS starts synthesizing the first sentence while the rest of the answer is still being generated. Time-to-first-word makes or breaks perceived latency in a voice agent, and on the booth machine ours hovered around 400 ms. That is the happy path. It is also the less interesting one. IVR is.
Granite Switch and the Core Library: validation as a first-class step
At the booth, validation was on by default. Instead of streaming tokens straight to TTS, every user turn triggered a Best-of-N parallel generation with live requirement checking. (The UI exposes a toggle to flip back to plain streaming, but most visitors saw the validation path.) This is where Granite Switch and the Granite Core Library come in, and they are the part of the 4.1 release we were most curious to put in front of users.
Granite Switch 4.1 is how the release approaches model composition. The standard way to ship a model that can do many specialized things is unhappy on both ends: keep one fine-tuned copy per capability and you multiply memory and compute, or merge adapters into a single set of weights and you blend the task specializations together until none of them really work. Granite Switch's answer is activated LoRA. Twelve independently trained LoRA adapters live inside one 3B-parameter checkpoint built on Granite 4.1 3B, and they are selected at inference time by control tokens in the chat template. A lightweight switch layer detects those tokens and emits per-position adapter indices that every decoder layer reads, so a contiguous span of tokens runs through one adapter, the next span runs through another, and the base model handles everything else. KV cache normalization keeps the adapters from sharing internal state. Each one only sees prior tokens through the base model's representation. The whole thing is a single HuggingFace / vLLM checkpoint, and selecting an adapter is a chat-template argument.
The twelve adapters are organized into three libraries. The Core Library ships three adapters for explainability and validation: context_attribution, uncertainty, and requirement_check. The RAG Library has five for retrieval-augmented generation: query rewrite, query clarification, answerability, hallucination detection, and citations. The Guardian Library has four for safety: a Guardian core, factuality detection and correction, and policy guardrails. The demo uses requirement_check, but a different demo could just as easily use answerability to decide whether the chat model should attempt a question at all, or citations to anchor every claim to a document span.
What requirement_check does is easy to describe: given a generated response and a plain-English requirement, it returns a calibrated score that the caller thresholds. No few-shot prompting, no heuristic regex over the output. The score matters. A boolean would force a single global policy; a calibrated score lets each requirement set its own threshold.
The plumbing for "use a Granite Switch model" is one extra line on top
of any OpenAI-compatible backend. The register_embedded_adapter_model
call tells Mellea that this checkpoint carries embedded adapters, so
when something downstream asks for requirement_check or
policy_guardrails, the request goes to the right adapter via control
tokens in the chat template — no separate endpoint, no swap, no second
process:
self._backend = OpenAIBackend(
model_id=LLM_MODEL,
base_url=LLM_URL,
api_key=LLM_API_KEY,
)
self._backend.register_embedded_adapter_model(LLM_MODEL)
For each user turn, the service runs BEST_OF_N (default 3) generations
in parallel, scores every candidate against every requirement (also in
parallel — nested: N candidates × M checks all in flight), and pushes
the first candidate whose requirements all pass to TTS as a single
LLMTextFrame. If none pass, a canned fallback answer is used:
with ThreadPoolExecutor(max_workers=BEST_OF_N) as executor:
futures = [
loop.run_in_executor(
executor,
_single_generation,
action, ctx, self._backend, model_options, IVR_REQUIREMENT_SPECS, True,
i, t0, emit,
)
for i in range(BEST_OF_N)
]
all_attempts = await asyncio.gather(*futures)
passing_indices = [i for i, a in enumerate(all_attempts) if a["passed"]]
if passing_indices:
chosen_index = passing_indices[0]
chosen = all_attempts[chosen_index]
else:
chosen_index = -1
chosen = {
"answer": (
"That's a bit outside what I can get into right now. "
"But I'd love to tell you about the new Granite release. "
"What would you like to know?"
),
"passed": False,
}
Gracefully redirecting beats emitting a response we know failed a check. The redirect string above is the booth-deployment text; the open-source reference ships with a slightly shorter version.
Every phase (start, sample_start, sample_text, check, done) is pushed to the browser as an RTVI server message, which is how the validation grid on the booth screen stayed live. Watching the grid fill in while the bot was still "thinking" was the demo.
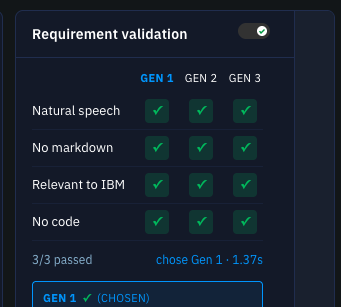
The trade-off is obvious. This path is not streaming. The full answer has to be produced before the adapter can score it, so TTFW goes up by the duration of one generation. For a demo where we want to show validation happening, that is the right trade-off. For a customer where sub-second TTFW matters more than guaranteed enforcement, streaming is still the right default.
Grounding with documents, optionally
For parts of the demo that need to be factually tight ("what sizes do the Granite 4.1 language models come in," "what's in the Core Library"), we rely on document grounding rather than the chat model's memory. Point DOCUMENTS_DIR at a folder of .txt files and the demo loads them at import time as Mellea Document objects, then embeds them in the system prompt inside <documents> XML tags:
_documents_block = (
"You are a helpful assistant with access to the following documents. "
"You may use one or more documents to assist with the user query.\n\n"
"You are given a list of documents within <documents></documents> XML tags:\n"
f"<documents>\n{doc_lines}\n</documents>\n\n"
"Write the response to the user's input by strictly aligning with the facts in the provided documents..."
)
The documents in the booth deployment cover each model family in the release (one per model) plus one describing the demo's own architecture. When a visitor asked about the 8B language model's training recipe, the answer came from text we'd written, not from whatever the chat model had absorbed at pretraining time.
What this adds up to
One WebRTC conversation, one Pipecat pipeline, and every layer of the
Granite 4.1 release doing something load-bearing. Granite Speech on the
way in. A Granite language model in the middle. Granite Switch's
Core-Library requirement_check and Guardian-Library
policy_guardrails adapters scoring each candidate. Mellea tying it
together. A TTS voice on the way out. The pieces were designed
independently and trained by different teams; the fact that they compose
without a rewrite is what we wanted to show.
Try it yourself
The whole speech app runs as a Colab notebook:
Open in Colab: granite_speech_demo.ipynb
What you'll need:
- A GPU runtime --- A100 (Colab Pro) recommended, L4 works, T4 will OOM. Both Granite models have to fit alongside each other.
- A HuggingFace read token as a Colab Secret named
HF_TOKEN. Used both to download the Granite weights and to mint per-session WebRTC TURN credentials so audio actually reaches your browser. - Chrome, Edge, or Firefox. Safari is flaky over WebRTC.
Then: set the secret, switch the runtime to a GPU, hit Runtime → Run all, and when the last cell prints a URL, open it and start talking.
The demo is a reference, not a product. But it's the shape of the applications we think Granite 4.1 is good for, and the easiest way to build intuition for how the pieces compose is to talk to one.