Making Small Models Rock with Mellea

Small open-weight models keep getting better. A 3B Granite model on your laptop today does things a 70B model couldn't do a year ago. There is still a gap between "small model can technically do this" and "small model can reliably do this on real data in production," and most teams cross that gap by giving up and paying for a frontier reasoning model instead.
They shouldn't have to. The reason a small model fails on most production tasks isn't raw capability; it's that the small model can't hold a six-subtask problem in one shot. A frontier model given a thousand-token system prompt with six subtasks inlined will muddle through. A 3B model given the same prompt won't.
The fix is a better harness around the model you already have. By "harness" we mean the software scaffolding around the model call: decomposition, validation, retries, tool dispatch. The part that isn't the forward pass. That's what Mellea is for.
What this post does: walks through a construction cost-estimation pipeline that one-shot prompting needs a frontier reasoning model for, rebuilt as a local Mellea pipeline. Granite 4 Micro 3B handles parsing, validation, and pricing; GPT-OSS 20B handles chart and report generation. No API keys, no egress, no per-token billing. If you're paying frontier-model prices for structured extraction or matching, the same pattern applies.
The Bet
Mellea is built around one observation: the software harness around a model matters as much as the model itself. Frontier labs already know this. The team training OpenAI's models knows exactly what the ChatGPT and Codex harnesses look like, and that knowledge shapes the training data. The open-weight ecosystem has mostly not had that feedback loop. You upload weights to Hugging Face and people do whatever with them.
Mellea is the harness side of that co-design. It takes tasks that currently demand a frontier model, breaks them into pieces a small model can do well, and holds those pieces together with ordinary code rather than an ever-growing English prompt.
Three things fall out of that approach:
- Cost is predictable. Local inference on a small model has a fixed, knowable cost per run, so you can back-test millions of runs without a finance conversation.
- Data stays local. Documents never leave the machine. For regulated domains like healthcare, finance, legal, and procurement, that's the difference between "can use this" and "can't."
- The inference backend is yours to choose. Mellea talks to Ollama, vLLM, Hugging Face, and any OpenAI-compatible endpoint, so swapping backends is a one-line change. You aren't married to one provider's pricing or uptime.
The Three Patterns
Mellea turns a task that needs a frontier model into one a small model can handle through three patterns:
- Decompose the task. A single prompt bundles parsing, fuzzy matching, arithmetic, and generation. Split it into steps narrow enough that a small model can nail each one.
- Externalize control flow. Keep the
forloops,ifstatements, and retry logic in Python, not in the prompt. Models don't need to be instructed to iterate; code iterates. - Modularize model capabilities. Reuse validated components like structured output, typed generative functions, and RAG adapters instead of rebuilding them every time.
None of these is new. They are the ordinary software-engineering moves you would make for any non-trivial system. What's new is applying them to the part of your program that happens to be written in English.
The argument in On the Foolishness of "Natural Language Programming" from 1978 applies directly. Dijkstra's line:
The "naturalness" with which we use our native tongues boils down to the ease with which we can use them for making statements the nonsense of which is not obvious.
A modern model interpreting English well enough to try doesn't change that. Drawing boundaries, stating contracts, decomposing work: that's where the engineering has always lived. The syntax of the target language was the trivial part.
An Example Worth Walking Through
Pick a task that's just past what single-shot prompting can do reliably, then build it up as a small-model pipeline.
A construction management firm wants to estimate material costs for a project. The inputs are a construction plan (PDF, with a bill of materials spread across several tables) and a handful of supplier catalogs (PDF, DOCX, XLSX). The output is a priced HTML report with a pie chart breaking spend down by category.
Ask a frontier model to do this in one shot and you can mostly make it work. A top-tier reasoning model with extended thinking gets most of the line items right, cites the catalog it pulled the price from, and does it all for about a dollar per run. Here's what one-shot prompting looks like across the size spectrum:
| Model | Result |
|---|---|
| Small open-weight (<3B) | Doesn't understand the task. Returns a generic "cost breakdown" with no prices. |
| Open-weight reasoning (gpt-oss-20b, one-shot) | Finds categories and subtotals. No pie chart. Numbers often wrong. |
| Gemini Flash | Mostly reasonable. No chart. Some prices off. |
| Frontier reasoning (GPT-5) | Gets most items right. Cites sources. No chart on first shot. On the order of a dollar per run. |
That sounds cheap until you write down what the firm actually wants to do with it. Fifteen hundred projects a year, twenty years of history, a backlog of hypothetical backtests: what if we'd switched lumber suppliers in 2012? What happens to margins if this supply chain constraint materializes? One backtest is a Monte Carlo simulation over tens of thousands of projects. At frontier-API prices, that's the budget for a small team.
Same task, as a local Mellea pipeline. Local models handle parsing, validation, pricing, and chart/report generation instead of routing the whole job through a frontier API. A few hundred lines of pipeline code, no API keys, no egress, no per-token billing. Here's how.
Note: The snippets below are the load-bearing pieces of the pipeline, trimmed for reading. The full runnable notebook has the install commands, sample data, and the glue between steps.
import mellea
from mellea.backends.model_ids import IBM_GRANITE_4_MICRO_3B
m = mellea.start_session(backend_name="ollama", model_id=IBM_GRANITE_4_MICRO_3B)
Step 1: Parse the Construction Plan into a Bill of Materials
The construction plan is a PDF with tables scattered through it. Some are
bills of materials; others are schedules, notes, or summaries. The first
step is to get a clean, typed BOM object.
RichDocument wraps docling and
exposes tables as markdown, which small models handle much better than raw
HTML or PDF binary:
from mellea.stdlib.components.docs.richdocument import RichDocument
plans = RichDocument.from_document_file("construction_docs/construction_plans.pdf")
To filter down to material-list tables, Mellea lets you declare a typed generative function: a Python signature with no body, plus a docstring.
from typing import Literal
@mellea.generative
def is_material_list(table_markdown: str) -> Literal["yes", "no"]:
"""Determines if the table contains a list of construction items."""
The @mellea.generative decorator turns the signature into a constrained
model call. The return type Literal["yes", "no"] forces a binary answer at
decode time. The model can't hedge with a paragraph, can't return "maybe,"
and can't return "probably yes." That constraint is enforced by the
sampler, not by a post-hoc prompt rule.
For tables that pass the filter, reformat them into a validated BOM:
import pydantic
class BOMEntry(pydantic.BaseModel):
item: str
quantity: int | str
notes: str
category: Literal["lumber", "windows", "doors", "other"]
class BOM(pydantic.BaseModel):
items: list[BOMEntry]
The schema pins the shape. But "quantity" has a construction-specific quirk: alongside integers, entries can read allowance — meaning buy some of these, here's twenty bucks. The Pydantic schema alone can't express that rule, so it goes into a requirement with an explicit validator:
from mellea.stdlib.requirements import req, simple_validate
def _quantity_is_valid(out: str) -> bool:
bom = BOM.model_validate_json(out)
return all(str(e.quantity).isdigit() or str(e.quantity).lower() == "allowance" for e in bom.items)
m.instruct(
"Reformat this table to have four columns: item, quantity, category, and notes.",
grounding_context={"table": table.to_markdown()},
requirements=[req("Quantity must be an integer or 'allowance'", validation_fn=simple_validate(_quantity_is_valid))],
format=BOM,
)
Two layers of enforcement: format=BOM constrains the decoder to emit valid
JSON matching the schema; the requirements list adds business-logic checks
on top. If validation fails, Mellea re-samples. The loop is Python; the model
only has to do the reformatting.
Parallelize across tables
Construction documents often carry many tables, and each table is
independent of the others. The full notebook fans out with ainstruct:
boms = await asyncio.gather(*[reformat(t) for t in material_tables])
One coroutine per material-list table, gather merges the resulting
BOM objects. Wall-clock scales with the slowest table, not the sum.
The loop shape stays in Python.
Step 2: Load the Product Catalogs
Catalogs come in whatever format the supplier happened to send. RichDocument
handles PDF, DOCX, and XLSX the same way:
from mellea.stdlib.components.docs import Document
def load(path: str) -> Document:
return Document(text=RichDocument.from_document_file(path).to_markdown())
doors_doc = load("door_catalog.pdf")
windows_doc = load("windows_catalog.docx")
Each becomes a plain Document, the input format Mellea's RAG adapters
expect. Any item whose category isn't keyed into the catalog lookup below will
land in the report as "unknown."
Step 3: Match BOM Entries to Prices with RAG Adapters
Matching "36x80 Aurora half-moon entry door" from a bill of materials to the right line in a product catalog is fuzzy by nature. Rather than ask a general-purpose model to "find the right price and tell me if you're sure," put a calibrated gate in front of extraction.
The adapters run on the HuggingFace backend, so start a second session:
from mellea.backends.huggingface import LocalHFBackend
from mellea.stdlib.components.intrinsic.rag import check_answerability
from mellea.stdlib.context import ChatContext
m_hf = mellea.MelleaSession(backend=LocalHFBackend(model_id=IBM_GRANITE_4_MICRO_3B))
check_answerability is the RAG adapter we'll use as our gate: given a
question and a document, it returns whether the document actually contains
enough information to answer. The line that matters is the answerability
gate (if verdict != "answerable":) sitting in front of extraction. The loop walks every BOM item, picks the
right catalog by category, and asks the answerability adapter whether a
price is extractable before it ever asks the model to produce one:
CATALOGS = {"windows": windows_doc, "doors": doors_doc}
def price_one(entry: BOMEntry) -> tuple[float | None, float | None]:
catalog = CATALOGS.get(entry.category)
if catalog is None:
return None, None # no catalog for this category → unknown
verdict = check_answerability(
f"What is the price of {entry.item}?",
documents=[catalog], context=ChatContext(), backend=m_hf.backend,
)
if verdict != "answerable":
return None, None # adapter isn't confident → unknown, not hallucinated
unit = extract_unit_price(entry, catalog) # m.instruct, format=...
total = extract_total(unit, entry.quantity) # m.instruct, format=...
return unit, total
verdict == "answerable" is a gate: items the adapter can't confidently
answer don't get a hallucinated price, they get total_price=None and
flow through to the report as "unknown." Failure modes are explicit. And
the model is only ever asked to extract a number from a document where a
calibrated adapter has already confirmed the number is there. The hard
problem (is this the right document at all?) was solved by a
specialized adapter rather than by a general prompt.
What makes these adapters worth reaching for, as opposed to asking a
general model "is this document relevant, 1-10," is that the outputs are
calibrated. Pass the doors catalog and a doors question, you get a
high-confidence "answerable". Pass the lumber catalog with the same doors
question, and answerability correctly collapses to "unanswerable".
Frontier model logits don't give you this. Nothing in a general-purpose
model's training signal makes the raw next-token probabilities mean
"calibrated confidence that this document answers this question." Adapters
are trained to make them mean that.
The same adapter family also supports context relevance and citation finding. Granite adapters ship as ALoRA adapters — activated low-rank adapters that switch on only for the adapter's own forward pass, leaving the base model's KV cache from the document prefill intact. Running answerability, context relevance, and citation finding over the same long document reuses that one prefill instead of paying for it three times. You get modularity without paying 3× the compute.
Step 4: Generate the Report
The final step is two instructions: make the chart, then write the report around it.
Pricing runs on a 3B Granite model, but chart-drawing code is a different
beast. Tool-calling and matplotlib benefit from a model with more muscle,
so for this step switch sessions to GPT-OSS 20B running locally on Ollama.
The same m name now points at the larger model for the remainder of the
pipeline:
from mellea.backends.model_ids import OPENAI_GPT_OSS_20B
from mellea.backends.model_options import ModelOption
from mellea.stdlib.tools import local_code_interpreter
from mellea.backends.tools import MelleaTool
m = mellea.start_session(backend_name="ollama", model_id=OPENAI_GPT_OSS_20B)
The chart step hands the model a tool and lets it drive:
chart = m.instruct(
"Use the code interpreter to create a pie chart of cost breakdowns "
"by category. Save it to /tmp/chart.png.",
grounding_context=report_ctx, # {item: {total_price, category}} for each priced row
tool_calls=True,
model_options={ModelOption.TOOLS: [MelleaTool.from_callable(local_code_interpreter)]},
)
chart.tool_calls["local_code_interpreter"].call_func()
Then a plain instruct writes the HTML report around that image:
report = m.instruct(
"Write an HTML report with a top-line cost breakdown by category and a "
"line-item material list with prices. At the top include /tmp/chart.png.",
grounding_context=report_ctx,
)
Swapping sessions mid-pipeline is one line. Each step runs against the model that suits it: tiny and cheap where the task is narrow, bigger only where the task demands it.
The chart is drawn by actual Python code executing on actual data, not by a model emitting numbers and hoping they line up with the totals elsewhere in the report. The grounding context is a plain dict, not a vector store. When the context is small and structured and known at call time, passing it directly is simpler and more predictable than dragging in retrieval.
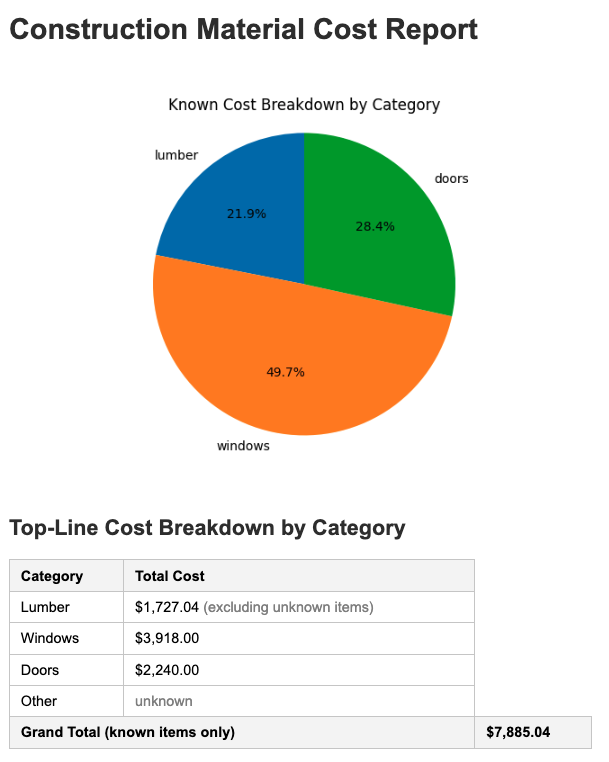
Here's what the pipeline actually produces. The chart and top-line table:
And the line-item list, where every row is either a price extracted from a
catalog or an explicit unknown:
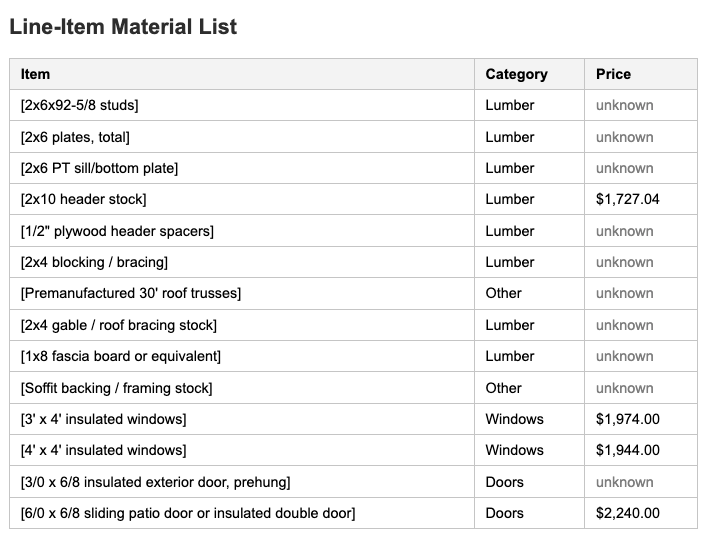
The grand total ($7,885.04) is the sum of known items only. Lumber items
have no catalog wired up in this run, so they short-circuit to unknown
before the adapter is ever called — and the lumber row in the top-line
table is annotated excluding unknown items so the gap is visible at a
glance. The same outcome applies when a catalog is present but the
answerability adapter isn't confident: the row stays unknown rather
than getting a fabricated price. That's the property worth checking —
not that every row gets a price, but that unsupported rows fail loudly.
Small Models, Production-Ready Output
Step back from the construction example. The general shape of the trade:

A task that one-shot required a frontier model and a dollar per run now
runs as a local pipeline with smaller models doing the narrow parts. Pricing
extraction runs on Granite 4 Micro 3B via HuggingFace; chart and report
generation run on GPT-OSS 20B via Ollama. No API keys, no egress, no
per-token billing. Items the pipeline can't confidently price show up as
unknown in the output rather than as hallucinated numbers, so the report
is auditable instead of something a human has to re-check line by line.
The construction case isn't a one-off. The same three-pattern approach generalizes. The Mellea team has been porting prompt-heavy agents (a DB2 database agent and a compliance agent) to the same decompose / externalize / modularize shape, and the practical effect is what you'd predict from the construction pipeline: the steps the small model is now asked to do are narrow enough that it can do them, and the steps that still need a larger model are isolated to where they actually matter. The harness is what buys you that separation.
The win is not that one tiny model does everything. The win is that the harness lets narrow steps run on tiny local models, reserves larger local models for the few steps that need them, and keeps control flow, validation, and failure handling in code. If you're paying frontier-model prices for a task that decomposes cleanly, there's a good chance you're paying for engineering you haven't done yet.
Trade-offs
Wall-clock per run is higher than a single API call. Each individual step is usually faster — smaller model, no network — but a pipeline with several serial steps adds up. Async execution hides most of the fan-out within a step, not across them. The win is in cost, privacy, and auditability, not in tail latency.
Rate limits disappear. A frontier API can rate-limit you mid-backtest; local inference can't. When a pipeline fails at 3am, debugging a decomposed Mellea program means finding which step went wrong — a single frontier-model call is a black box. And the obvious alternative to "better harness + small model" is "fine-tune a small model." Harnessing is cheaper to iterate on and composes with fine-tuning later if you need it.
Decomposition takes engineering effort. It's ordinary software work — a senior engineer can typically port a prompt pipeline in a day or two, and the GPU or laptop amortizes fast compared to even a week of frontier-API backtests. It pays back once the task is recurring, privacy matters, or cost compounds at scale.
Not everything decomposes. Tasks that are genuinely holistic, like free-form creative writing or long-form reasoning chains that cannot be separated into clean intermediate states, still favor a big model. Know which kind of task you have before you invest.
Try It
If you're running structured extraction, matching, classification, or report-generation pipelines and paying frontier-model prices for it, the pieces used above are all part of Mellea's standard library. The full construction tutorial notebook is in the Mellea tutorials repo.