Why Mellea?

This post is adapted from a keynote talk at All Things Open 2025, "From agent soup to proper software design: Mellea puts developers back in control". If you'd rather watch than read, the video covers the same ground.
Agents are the topic on everybody's mind, and it's safe to say they're a disruptive force. The headline of the moment is that agents are eating software: every app, every SaaS product, every workflow is supposedly about to be rebuilt as an agent, or replaced by one. The hype carries a strong sense that everything is going to become an agent.
That's the good part, the hype-cycle part. The counterpoints are increasingly coming out. A study from MIT estimated that something on the order of 95% of AI pilots were failing, and that businesses were going to have to react to that fact. Not everyone shares quite that high a number, but across the field, an 80% or 90% failure rate seems to be pervasive. So on one hand it's going to eat the world, tremendous potential; on the other, most of these projects are failing. Where does that leave us? In the indigestion phase of this whole endeavor.
Agents are just programs
So what's going on? Agents are obviously a big buzzword. The word isn't actually very precisely defined; everyone means something different, and people tend to call everything an agent. But consider a minimal canonical example. The classic ReAct pattern has the model do progressive loops through a prompt: it does a thought, then an action. The action is an API call; it gets some information, brings it back, then observes and decides what action it wants to do next. It's a looping primitive.
A little further into the research field is inference scaling, where models spend more time doing inference to come up with better answers. Some of that's just models thinking for longer: they produce long chains of thought where they reason "well, if this is true, then that must be true," and so on. But there's also a category where they fork multiple threads of that long chain of thought and then combine those together, taking the best one, merging them, or doing a search over them, to get a parallel fork flow.
Here's the claim. All of these things get reified as separate, distinct things, but really, "agents," "agentic," and "inference scaling" are all just names for programs: different patterns of control flow around the use of generative AI. That's not a profound statement; it's a little reductive. But it's powerful, because the industry is leaving tons of value on the table by treating each of these as a different thing when in fact there's lots of stuff in between. There are many patterns available for agents, and they don't all need bespoke names tied to one application. There are lots of ways to use inference scaling casually, or use agentic-like patterns, without having to make everything be an agent.

So if all agents are really just programs, and all inference scaling is just programs, why doesn't it feel like programming, and why is the failure rate so high? A 95% failure rate for software projects would cause some pretty nervous times in any software development shop.
Why it doesn't feel like programming
The primary interaction point with models is through prompts. You write some natural language and prompt the model. For interacting with ChatGPT or Gemini or one of these consumer chat applications (which are themselves really agents, software plus a model), that's no big deal. These are brief, interactive, iterative exchanges.
The problem comes when you want to build an application, especially an enterprise application, where it needs to do the right thing most of the time. The prompts get longer and longer. Anyone who has seen one, or written one, knows it reads like a list of instructions. They start with a whole backstory for the model: "you're a site reliability engineering agent, you do this, and if you see this, you have to do that." The prompts grow into whole pages, then books, until pretty much everything is just prompts.
The issue is that it's not maintainable. The software industry spent decades figuring out how to maintain and collaborate around code, but there's no equivalent way of thinking about how to collaborate on and maintain a 10,000-word essay. And these enormous prompts are everywhere. There are a number of problems with this that are ultimately leading to a lot of the failures we see today.
Security by prayer
Consider an example, adapted from a real prompt with the specifics changed. It contains sections like this:

What the author is trying to do here is make the thing more secure by basically asking the model nicely to be more secure. Ask any security expert whether that's legitimate, and the answer is no. Security by obscurity is not security. This is security by prayer: pleading with the model, please, please don't be insecure. That isn't going to cut it. It isn't secure by design, and that's a problem.
The scars of prompt engineering

Another section in the same kind of prompt shows a different tell: IMPORTANT! and
you MUST in all caps, brackets around something, lots of capital letters, lots of extra
exclamation points. This is not a natural way of talking; people don't talk this way.
These are the scars of prompt engineering. The reason someone put "not" in caps is
that the model kept doing the thing, so they went "no — NOT," capitalized it, and added
exclamation points. It's finicky. Prompt engineering is not particularly engineering-like,
because there's no real rhyme or reason to why any of these maneuvers help on any
particular prompt.
The bigger problem: even once a prompt works (an annoying process), it works on one model. Switch to another model vendor and it's a completely different game; the prompt has to be redone to work with that model. This is true across the entire spectrum, big models and small models alike. So prompts aren't portable, and that's a huge problem. Really talented engineers have threatened to quit rather than do any more prompt engineering. It was soul-destroying.
Which raises the question of whether there's a way to do this differently, and maybe better.
Enter Mellea

Mellea is a project whose spirit is to make generative AI more like software. It's built around the notion of generative computing: the idea that generative AI is itself a kind of computing element that weaves into the regular fabric of computer science. It lets you use generative AI in any program. You don't have to be building an agent; you can use a little bit of GenAI anywhere you'd like. But you can write agents if you want to.
And agents, most of the time, once you unpack them, are just a loop, a bit of a loop with some control flow. It's not hard to write an agent. Sometimes the agent frameworks are actually getting in the way. Mellea works with any agent framework, but it doesn't require one to write an agent. The goal is to make everything more predictable, maintainable, composable, and secure.
What follows is a brief flavor of how it works.
Write Melleic Mellea
The first rule of Mellea programming: you write in Python. And you don't just write in Python, you write Pythonic Python. You don't just write in Mellea, you write Melleic Mellea code.
import mellea
m = mellea.start_session()
answer = m.chat("tell me some fun trivia about IBM and the early history of AI.")
print(answer.content)
Don't let the LLM own the control flow
This is one of the commandments of Mellea, and of generative computing in general. Abdicate control flow to the model and you lose the ability to insert checks, to verify that a condition was actually met. (The lawyers really care about this one.)
The other thing about control flow is that it's something models are incredibly bad at. On benchmarks like ComplexBench, the very best modern frontier models only get into the 80s. That means they fail about one in five times on simple control flow: nesting conditionals, or even just doing things in the right order. Anyone who has done prompt engineering has seen it: give the model a list of actions and it'll just not do one of them, and then it has to be coaxed back into working. So don't let the LLM drive the bus.
Instructions, not prompts
Mellea's first move on that front is to shift to instructions, not prompts. The goal is to take advantage of the LLM's remarkable ability to understand and use natural language without creating long prompts, by breaking them up. Mellea has a notion of an instruction that makes it easy to take a small section written in natural language and intersperse it into code.
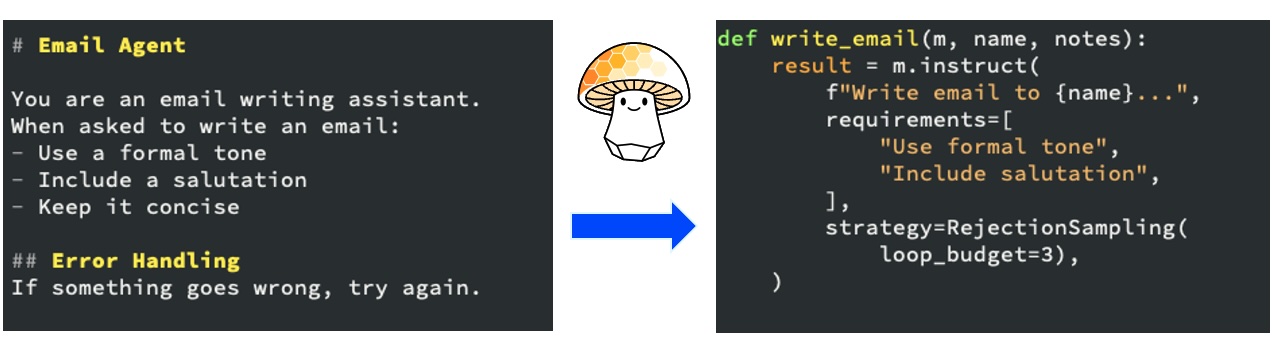
This can yield up to 20-point improvements in the satisfaction of a given agent prompt, simply by breaking it into pieces, letting the host language (Python, say) do the control flow and letting the LLM do the part it's good at. It's about division of labor. It gives you much more control, and it gives you debuggability: instead of a monolithic prompt where something goes wrong with no way to debug it, you have small pieces. This is a simple thing; no framework required.
Embrace unreliability
But Mellea goes one step further. There's a line worth repeating: the second most remarkable thing about LLMs is that they can understand and produce fluent natural language. The most remarkable thing about them is that they do the wrong thing 5 to 50% of the time. (It's attributed, dubiously, to Winston Churchill; take the provenance with a grain of salt.)
This isn't a knock on LLMs. They're incredible. They can do things that would have been unimaginable just a few years ago. But they're unreliably amazing. What's needed is a framework that embraces the fact that these are unreliable systems: a programming model where uncertainty, and getting the wrong answer, is a first-class concern.
A pattern for generative AI: Instruct–Validate–Repair
To that end, Mellea introduces software patterns for generative AI. The first is called Instruct–Validate–Repair (IVR). Much as Model-View-Controller did for building UIs (a simple pattern that just made everything better), there are similar patterns waiting to be found for generative AI.
requirements = [
req("The email should have a salutation"),
req("Use only lower-case letters",
validation_fn=simple_validate(lambda x: x.lower() == x)),
check("Do not mention purple elephants."),
]
def write_email(m, name: str, notes: str) -> str:
email_candidate = m.instruct(
"Write an email to {{name}} using the notes following: {{notes}}.",
requirements=requirements,
strategy=RejectionSamplingStrategy(loop_budget=5),
user_variables={"name": name, "notes": notes},
return_sampling_results=True,
)
if email_candidate.success:
return str(email_candidate.result)
else:
raise AutomationFailedException(...)
IVR lets you express, simply and in broken-up language, "here's an instruction, here's a set of requirements it should meet," and Mellea takes care of the rest: reflecting automatically, doing targeted rewriting, checking the output, raising an error when the requirements aren't met, and trying again when there's something it can fix.
IVR is just a first flavor of what Mellea makes possible. It's the kind of thing that should take generative AI from something frustrating and prone to failed pilots toward something you can actually program against: more predictable, more composable, more reliable.
If agents are programs, the way to build them is to program. That's the bet Mellea is making.
Next steps
- Watch the talk this post is based on: From agent soup to proper software design: Mellea puts developers back in control (YouTube)
- See why small models rock: Making Small Models Rock
Get started: pip install mellea · docs.mellea.ai · github.com/generative-computing/mellea